
With ChatGPT raging, I explored building a chatGPT-based chatbot from scratch. This exercise aimed to see if we could tune a custom GPT model based on one’s data. There are two ways to fine-tune the GPT model for this purpose. Either consume the data and use some RAGs to train the bot or fine-tune the model using prompts in a user <> system message format.
Fine-Tuning the GPT model
In reality, both approaches are complementary, but thus, the exercise is about fine-tuning since one can play around with the tone and give the bot some personality. You can do all this using notebooks and paid access to GPT. Rest assured, we hardly spend a dollar trying this out a few times. The whole thing took a couple of hrs. The only major issue was the JSON format issues, but once we figured it out, we could tune and play with a custom model trained on our data + prompts. The only problem here was the tuning piece.
The first step would be to install the OpenAI python package locally to process the input training files and push them to OpenAI through their APIs. This is the first step to building your custom ChatGPT chatbot from scratch.
A quick conda install works + validates the installation by checking for Openai’s version. The alternative way is to use pip install openai.
From here forth, there are two steps to creating your first custom GPT chatbot. We will need to make the training set that will be used to train the model. We will follow this up with a few commands using the OpenAI package to be able to do the training.
The data is a collection of messages in JSON format and should be a .jsonl file. There is a strict file structure, and failure to adhere will result in a BadRequestError.
Training File Structure
Message 1
{“messages”: [{“role“: “system”, “content“: “You are a sales agent that tries to help prospects on an ed-tech platform by understanding their question and capturing their core intent and finally answering the question in a precise manner.”}, {“role“: “user”, “content“: “can we write aptitude tests here”}, {“role“: “assistant”, “content“: “Absolutely! JumboTech is a versatile platform for creating and conducting aptitude tests to assess candidates’ theoretical knowledge and problem-solving skills. I recommend that you share your valid business email ID and name so our team can reach out with help in the future!”}]}
Message 2
{“messages”: [{“role“: “system”, “content“: “You are a sales agent that tries to help prospects on an ed-tech platform by understanding their questions. The user is responding with one-word answers, and you need to invoke them to continue the chat”}, {“role“: “user”, “content“: “ok”}, {“role“: “assistant”, “content“: “I would like to confirm that you are satisfied with our response? I can share more details if you are interested. I recommend that you share your valid business email ID and name so our team can reach out with help in the future!”}]}
The file is a bunch of JSON messages with a structure, as mentioned above. There are three sets of role/content pairs. The first one sets the prompt for the chatbot type, its style, tone, etc, if any. The above is an elementary example. The other two pairs are a set of conversations exchanged between a potential user and the system, aka assistant here. In the training set, we mention the kind of question/statement from the user and an ideal answer/response from the bot. The above examples are two samples of the training set. To push a training job, one needs a minimum of 10 training samples.
Training Strategy
Their recommendations are between 50 to 100 good examples of fine-tuning and getting a decent chatbot. Our assessment based on the few training runs is the same; one should be able to get a reasonably decent bot with 50+ good training samples + the right kind of prompt setting for the bot.
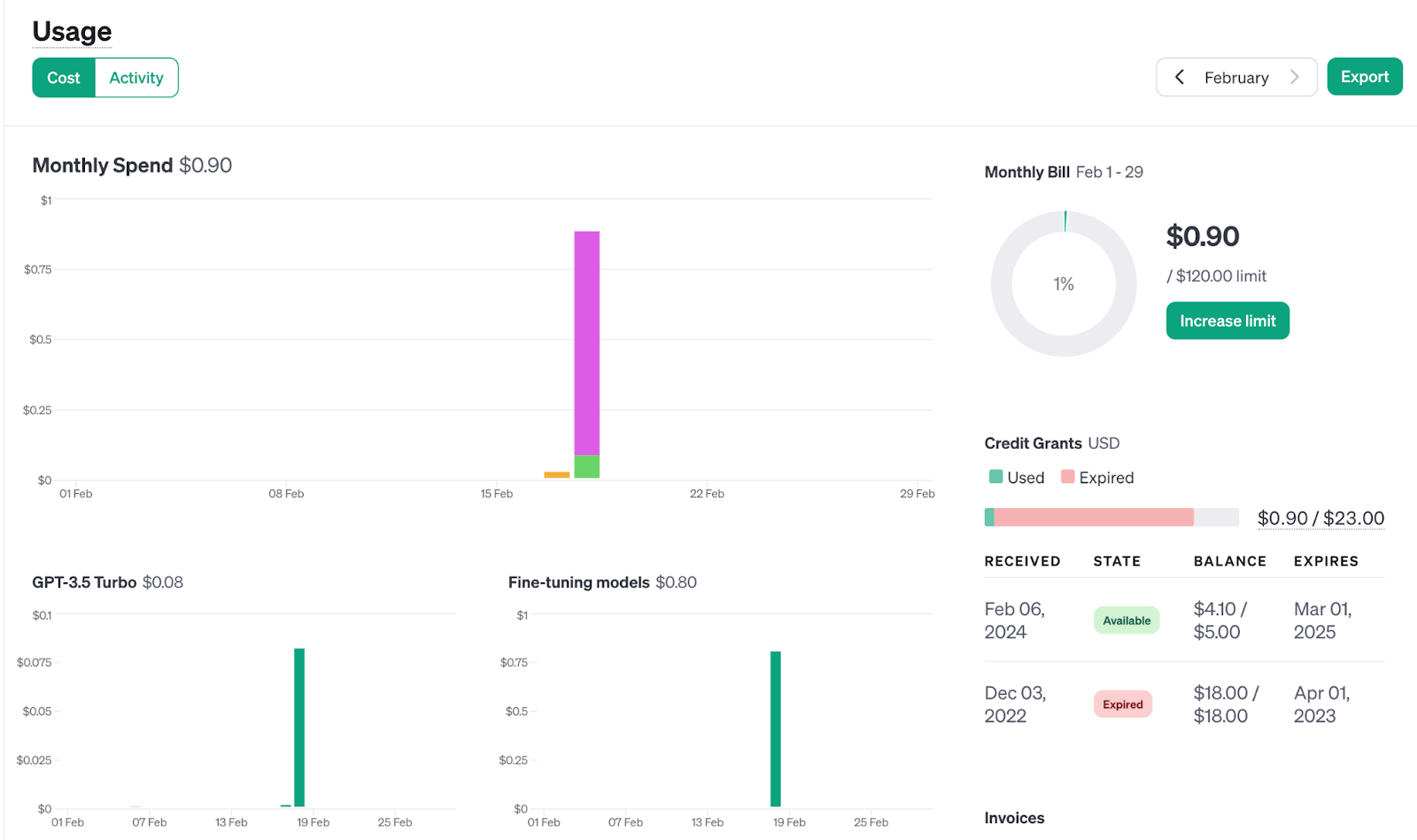
Usage & Pricing
Also, one can track the usage/cost of doing this training through the OpenAI dashboard. Alternatively, one can also estimate the training costs using code. This was a test experiment, and we could train three runs for a very minimal $1. The price is 1000 tokens. If you train a 10000-word text, aka 10000 tokens for ten epochs, you will get charged for 100000 tokens ~ 2 $. The detailed pricing is given here. Tokens charge both training and inference.
Code for file creation, formatting and other ancillary code/params to test training is covered in this OpenAI blog.
The other blog covers fine-tuning. You can push a training job quickly if the training file has the correct JSON format and at least ten examples.
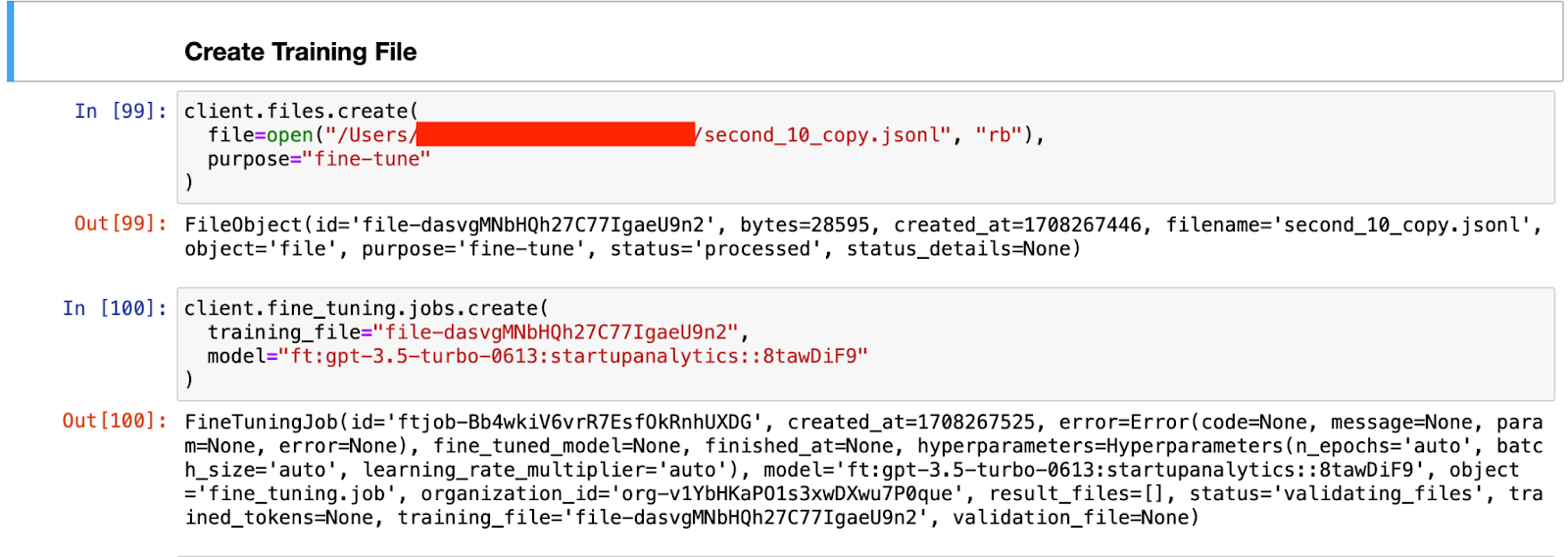
The second_10_copy.jsonl is the training file. It has ten examples. The second code snippet passes the training file ID from the first command post-processing and also mentions the model ID we are training. We wanted to update a custom GPT model we had already built, thereby mentioning its ID.
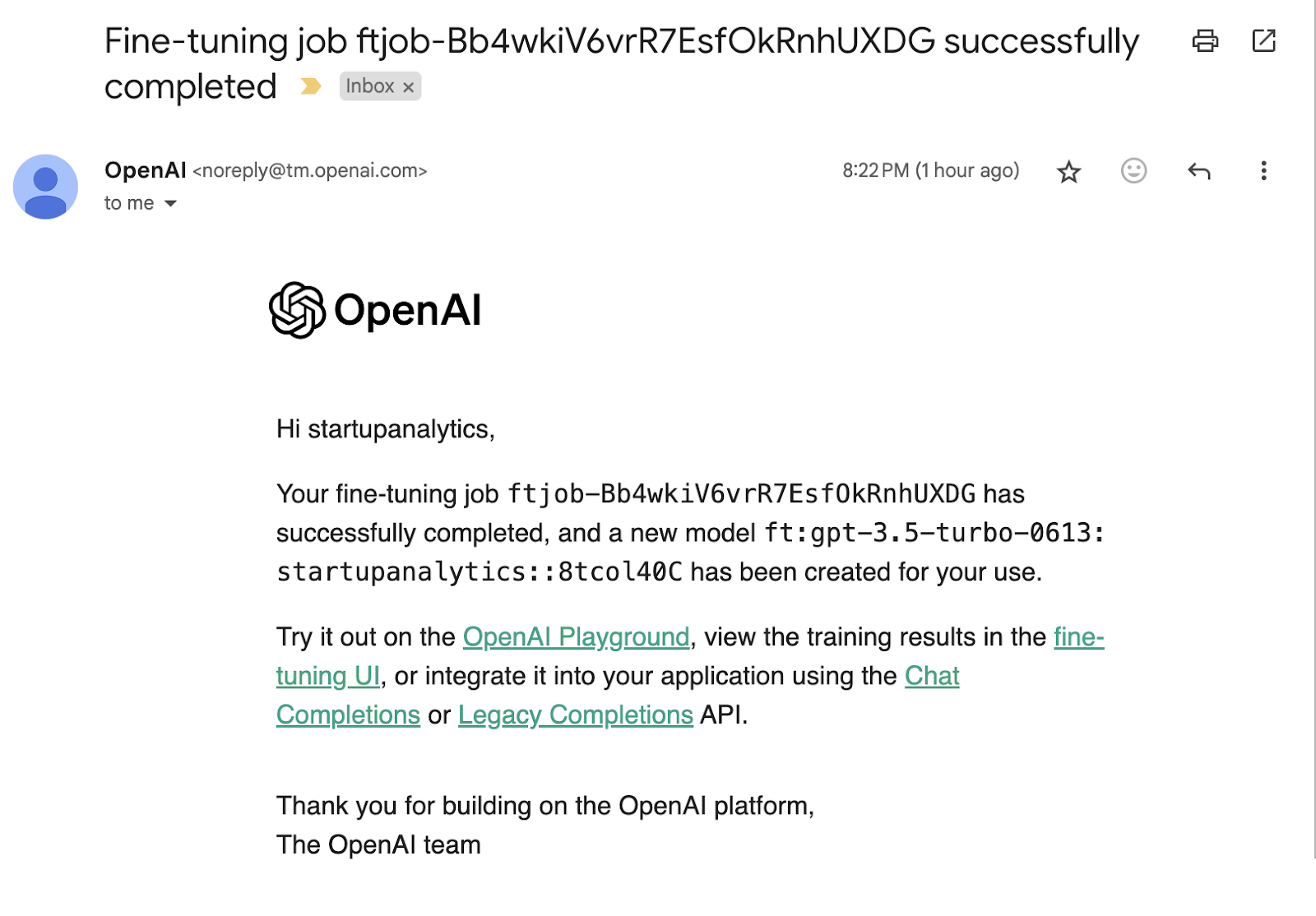
Post the job run, OpenAI shares an email with its status of either a successful run or a failure to run it in case of some possible failures post-processing of the training file.
Chat-GPT Playground
You can also play around with this custom GPT you build going to the playground. You can select any of your custom GPTs if you trained multiple versions.
It’s almost a similar interface, with the ability to type a message, and you would get a response from your custom GPT in the form of a chat.
There are a lot of customisations in terms of epochs, training size, temperature setting, and context length. But that’s for another blog. If you need the notebooks we used to run these jobs, test file validity, etc. Like, share and DM us. We’re happy to share to help you get over your first GPT model.
The ease of building a chatbot from scratch and the versatility of outputs make chatGPT now a viable startup analytical tool.
Reach Out at admin[at]startupanalytics.in